话说... 这是斯坦福大学的学生开发出的一套软件.....
他可以让让任何人做出任何表情... 包括说话的口型..
(这么描述可能有点拗口,不太能理解,我们就来继续看一下)
基本上,这个程序需要一段大概15秒的,目标人物说话的片段。。。 (甚至是youtube片段都可以)
通过这15秒的说话,程序就可以捕捉到目标人物A的整个面部表情。

会实时的根据面部表情生成一张3D的脸.....

与此同时... 软件用一个摄像头,可以捕捉操控者B的面部表情.....
在后台生成另一个人脸的3D模型....
接下来程序可以把这两张脸合并到一起.....

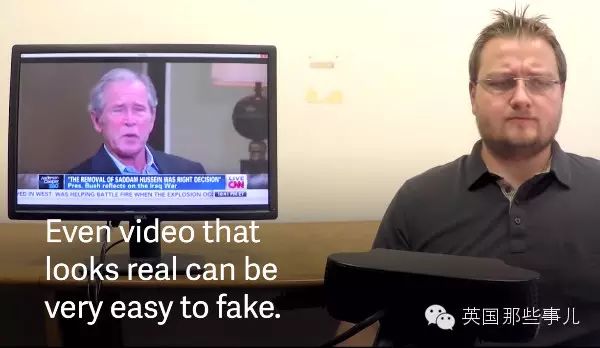
最终的结果??
这个程序就可以生成一段视频,让目标A作出跟操控者B一模一样的表情来.. 甚至是说话....
操控人B 目标A
 加拿大华人网 http://www.sinoca.com/
加拿大华人网 http://www.sinoca.com/

